
<Architect for Developers>
<To get a strong join, a clear split is needed first>
-rephrased well-known revolutionary expression.
Stereotypes of thinking are costly. If a person who lived half of life in a tiny dugout and suddenly gained the freedom to build whatever house for him/herself, it is likely that the new house will be large… dugout. If developers used to build Microservices with a focus on exchanging data, it is more likely than not that they will build a Microservice based on data exchange (via REST API/interface) even if they are asked to invoke the function/capability, represented by the Microservice.
Since business is about defining functions/operations and exchanging their invocations while technology is about exchange data, whey will never agree on the perception. The only option for technology to become really agile with business is to start modelling and mimicking business functionality, support functional invocation and, then, exchange data. This is how the world works.
The RESTful interface is naturally designed to work with data. The interface operations are not simple but rather primitive and limited, which we cannot say about functions in a business sense. So, when we are decomposing complex business applications into small uni-functional applications such as Microservices, developers still think “in data” and only in a data exchange manner. Isn’t this a paradox?
How can we return Microservices onto the functional road? Can we reuse REST for functional interactions and integration? REST operates with primitive basic verbs/actions – GET, PUT, POST, PATCH, DELETE, etc. – adopted from HTTP, which is a transport layer. When we use them at the application layer, we specify only those basic actions – we cannot even compose these basic actions together. The basic actions are usually enough to manipulate data, but the business world uses and needs a much richer spectrum of activities/actions. For example, we cannot request a Microservice to publish out specified report: 1) the report may appear too big; 2) written in unstructured language (not in JSON); 3) abilities of publishing via certain means and in particular environments may change frequently, i.e. the Microservice cannot notify all its consumers up-front all the time about changing the REST URI, which also will break backward compatibility with existing consumers. If we use a Command Pattern, we break fundamental principles of REST: it is like cracking nuts with the keyboard – we can use a keyboard as a nutcracker, but many will find this awkward. This is the problem we have to resolve if we intend to use REST for business tasks.
Why Microservices limit themselves to data exchange while they can be much more powerful and adequate to modelling real world business functionality? By the way, this modelling it precisely the method used when Microservices are composed into Microservice-based applications.
As many practitioners have noticed, the RESTful interface is good for relatively compact sets of data, but for exchanging significant volumes of data they are not the champions. Several years of practice show that transferring large sets of data in JSON format via HTTP is questionable from the performance standpoint and from the following processing (readability); in HPPTS it is even slower. If we add GDPR on the top of this and start to encrypt/decrypt personal data in the data volume, we need to think twice whether REST is the right choice. We might replace the singular volume by streaming, but REST is an uni-request-response model, i.e. it will be unnecessary chatty with streams.
In the market, there are many tools that make design, implementation and even deployment of data-centric Microservices a 10x-minute procedure, e.g. with Mule Soft’s Anypoint. People, especially a new generation of developers, when working with such tools have got a misleading message that Microservices are for data exchange only, Well, the industry had and has much more efficient means for moving data…
We call Microservices that are used to exchange data Informational Microservices. For the Microservices that exercise their natural purpose, i.e. aimed at functions and their interactions-exchange-integration, we need another name.
Over the years, IT and Business went their segregated ways. Partially, it was caused by the inability of technology to speak business language and vice-verse. Now, Business has adopted some technical jargon like ‘API’, ‘Big Data’, ‘AI’ and others, but the meaning of these terms is still based on the business, not technology, ontology. For example, saying API business means capability/function and even partner while technology means connectivity like a technical protocol; when saying Big Data, the first business impression is a big database, then, a magic analytics with the advisory predictions, which for the technology this is collection of variety of data obtained from different sources when the analytics is only a “next step”.
We believe that the significant part of this “Babylon” problem is that technology does not try to model business logic and comes up with its own. Before, this was caused by the size and cost of databases, but this ius not a limitation for several years already. If we are that smart to learn business models (not processes because they only reflect how business realised its models without digital power) and start building functionality-driven solutions, this will be the right time to start designing our applications in line with the business logic layer.
All right, the reader can say – ‘we did it all the time via UI and UX’. Yes, but the world behind UI had very little in common with business logic. If Microservices were oriented on their own functionality instead of data and capable to interact, compose collective efforts for complex tasks and deliver integral compound results, this could change the modern IT world. Such orientation makes Microservices the closest approximation of business capabilities, i.e. approximation to the language and means that business works with. We can resolve the problem of agility in this way. So, we call such Microservice type Functional Microservices.
The first and the foremost task on the way to modelling business logic is understanding how different functional business activities can be recruited to work together across application boundaries, and then – across administrative internal and external boundaries. “Working together” is based on two fundamental similar but still different concepts:
- Integration
- Interaction.
Before discussing each of these concepts, we have to outline that the uncooperative statement of Microservice Architecture about Microservice isolation in not only impractical from the business value perspective but also creates a lot of confusion and misconceptions between business and technology. This is especially undesirable during digital transformations. Recently, I saw a presentation from American Express about how they are solving the problem of still effective but barely supported Mainframes. They boxed and decomposed certain old functionality for card processing and constructed about 20-25 Microservices (in their terms) – everyone responsible not for a function but for a small domain. The manager who made the presentation said that each of these “big” Microservices engaged tens to a hundred Functional Microservice that were treated as independently deployable supplemental services designed for low-level functional interactions – business did not care about them. Indeed, since we construct our houses with basement, walls and roof, nobody carers abut individual brick or block – they have to stick together to form a particular part of the house. Microservices – simple functions – should inter-operate in order to produce collective value required by the business.
Integration is a well-known concept in technology. Integration is usually done at the function/logic level, e.g. we need two systems to integrate to collectively produce certain new value either via invocation of special functionality and/or via exchanging special data for known functions. In common cases, this functionality and data did not exist before integration is developed; if they existed, they were not supposed to be exchanged outside of the systems. That is, integration usually assumes that participants not only know about each other but also have to be modified somehowto perform required functionality or generate their own requests/events to the counterpart for the sake of the integration.
Interaction is more oriented on services. In interaction, participants do not need any internal changes caused by the purpose of collective work. For example, I am a passenger and I’ve got on the bus. I am not integrated with the bus though we move together. I am interacting with the bus knowing the rules and paying for the ride when staying inside. I know the rules for train, underground and airplane though they are absent in the case. My knowledge cannot be a means of integration. If this is not true, am I integrated with something I might think about while it does not exist or if I can forget something, does it mean I am not integrated with it anymore? If a Microservice sends a request “print” to the printer’s Print API, they are not integrated, they are interacting. The relative independence of Microservices and their different ownership together light the way to the interactions between them, which developers can capitalise on.
Summarising these observations, we are in a need for a type of Microservice interface that would allow Microservices to interact. The pre-conditions here are
- no degradation of performance compared to the simple data exchange provided by RESTful interface
- scalability, security, manageability and extendibility allowed by the interface
- programming language and platform agnostic of the interface
- tool support
- documentation and easy knowledge sharing.
We have found such type of interface in gRPC, now an open source. While it was initially developed for the data exchange similarly to REST, the presence of its own neutral IDL lets architects and developers define and describe the interface focused on functions and that can optionally support data. The gRPC is based on HTTP/2, which may be constructed to perform better than REST/HTTP1.1. Additionally, to meeting our requirements, this interface:
- Is strongly typed
- Can control whether the communication is secured (SSL/TLS)
- Allows independent encryption of data with no impact onthe usability
- Can generate consumer and provider libraries used as plug-ins in the related code-bases
- Supports versioning in the payload, i.e., again, does not impact usability
- Provides rich consistent error-handling
- Supports cashing and batching
- It can verify the failure and helps to fail fast.
From functional perspectives, there are two major benefits of gRPC:
- A Microservice with a gRPC-based interface supports the SOA concept of “consumer-service-consumer” – the fundamental aspect of inter-service interactions. An entity can play the role of a consumer in one interaction and, at the same time, play the role of a provider in another interaction. Microservices are not isolated anymore. Plus, consumer and provider can chat – exchange streams of messages defined in the single service – Google calls this “bi-directional communications”. Which message is sent by who in response to which messages from the counterpart is decided during the design. This opens an opportunity to negotiate better invocation compositions, functional error-handling and increase the robustness of the entire Microservice-based application
- An orchestrating Microservice can formally define non-trivial business logic using gRPC’s IDL. This allows for effective maintenance and management of distributed transactions across Microservices.
In the next step, we assume that Functional Microservices use gRPC API. Later on, we will show how we can compose functional invocation with optional data for processing via gRPC. But first, we have to make sure that Functional Microservices are distortionless in contrast to Microservice Architecture-compliant Informational Microservices. For this purpose, we have created a match/not-match table below for Functional Microservices.
| № | Distortionless characteristic | Matching |
| is a programming product | + | |
| focused on the realisation of a small, non-decomposable business function | – | |
| may have a few interfaces | + | |
| has a working body that implements predefined functionality | + | |
| preserves loose-coupling between its interfaces and working body | + | |
| is built for reuse | + | |
| can participate in as many compositions with others and can organise as many such compositions as needed | + | |
| has to consider its execution context, especially in defining its SLAs (per interface) | + | |
| can work within Applications or SOA Services; can cross Application boundaries, but may not cross SOA Service boundaries | + | |
| may be managed/governed centrally or de-centrally | + | |
| should be designed and deployed in a fault-tolerance manner or offer other means to fail-over for any types of failures – internal or external | + | |
| Microservice should be able to process any data presented in the owned meta-model | + | |
| The body can encapsulate any internal transactional operations and may be used in any distributed transactions that do not require locking | + | |
| is not obliged to maintain transaction-related data for the duration of an external transaction | + | |
| the granularity of the body should not necessarily be reflected in the interface | + | |
| can be designed, built and tested by different people; can be designed and built in relative separation from others while all aspects of intercommunication of having to be agreed and appropriately designed in the context of others | + | |
| should be minimally dependent on the run-time environment | + | |
| has to be accurately documented (automatically or manually), especially its functionality, contexts, SAL and outcomes | + | |
| should follow related policies with regard to used programming languages, error-handling, quality assurance, security, compliance, manageability and support operational patterns | + |
As you can see, only one characteristic does not match – “focused on the realisation of a small, non-decomposable business function”. This is because Functional Microservice can orchestrate the work of many other Microservices and such orchestration may be not a small simple function. If an orchestration is not needed, a leave (the smallest functionality) Functional Microservice does match all distortionless characteristics.
We cannot agree with old (2011) definition such as this: “Functional Integration – the logical extension of data integration – is where the applications integrate at the business logic layer by allowing the business function in one application (the source) to be accessed by other applications (the target)”. Since functions and capabilities can be composed and interact with no data whatsoever, it is the data integration is a consequential “logical extension” of functional integration. Without functions, there are no definitions of business information and no meanings or criterions of data integration.
Here are two examples of Functional Microservices. In the examples, we use the proto3 IDL for describing the Microservice’s gRPC interface. Microservice’s body is the code behind the interface code. The IDL key-word “message” identifies the smallest unit of byte-pack transferred via the wires.
#1. Function only
This example defines the Microservice’s gRPC interface that accepts a command from the consumer and returns the status of the requested operation/action.
syntax = "proto3";
// option… - placeholder for optional instructions for //compilation into particular programming language
package publishing;
// Definition of Functional Microservice’s interface
service PublishingService {
// This RPC interface accepts consumer’s commands for //executing different functions-features offered by the //Functional Microservice. The nomenclature of the commands //can vary. New commands may be added without preliminary //notes to the consumers. If a command is changed or removed, //it is recommended to notified all consumers off-line.
rpc executePublish(CommandRequest) returns (stream RetortResponse) {}
// If execution of the service fails due to any reasons other //than connectivity to the service, the error-message is //turned to the consumer.
// If the requested command does not match any one offered, //the service returns an error-message and a list of available //commands to inform the consumer.
// If requested commend is accepted, service returns a stream //of retorts with the first message confirming the acceptance //of the command. Upon command completion successfully, the //second retort about completion is returned or the retort //becomes an error-message.
}
// message confirms receiving a command from the consumer
message ReceivingConf{
string received = 1;
}
// message reporst completion oif command execution back to the consumer
message CompletionConf {
string completed = 1;
}
//If service has a problem/error during its execution and //cannot complete the command, it reports a failure back to //the consumer. Details are optional.
import "google/protobuf/any.proto";
message CustomError {
string error_comment = 1;
//not very long list of ‘detail’ messages associated with
//returned error
repeated google.protobuf.Any details = 2;
}
// List of available Commands. Used to notify the consumer if //the non-existing command has been requested.
message CommandList {
repeated Command cmd = 1; //contains a list of commands of current CommandType.
// List can vary over the time – be extended or shrank
}
message Command {
enum CommandType { // just an example
COMMAND_UNKNOWN = 0;
PRINT_HIGH_QUALITY = 1;
PRINT_DRAFT_QUALITY = 2;
PRINT_&_INTERNAL_DISTRIBUTE = 3;
PRINT_&_COMPLIANCE_DISTRIBUTE = 4;
}
CommandType command = 1;
//may not be NULL, i.e. the value-field is required
}
// The “choice” operation is not supported in the IDL. The //messages to be returned in each particular case have to be //meaningful while the others should be set set to NULL
message Retort {
ReceivingConf receiving = 1;
CompletionConf completion = 2;
CommandList = 3;
CustomError executionError = 4;
}
// service input
message CommandRequest {
Command command = 1; //may not be NULL - required
}
// service outcomes
message RetortResponse {
Retort retort = 1; //may not be NULL - required
}A figure below illustrates a potential taxonomy of Microservice invocation with gRPC and REST interfaces.
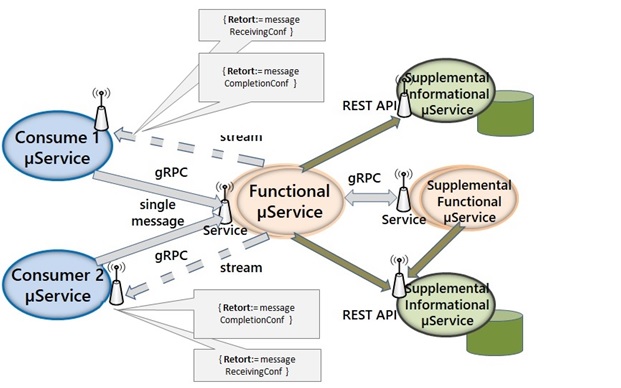
The gRPC is used for functional invocations of Microservices, the REST API is used for informational/data operations via Microservices. There are no limitations on using REST API for Functional Microservice if its data is needed, but gRPC is more efficient even for that task.
Function and Data
This example defines the Microservice’s gRPC interface that accepts a command and data sent by the consumer to the provider. There are two possible cases depending on the volume of the data passed via gRPC.
In the first case, the data-sets are relatively small – less than several MB. That is, we can specify a few data-set implicit messages of less of 1 MB each in size. For this, we have to modify only Command message from #1.
message Command {
enum CommandType {
COMMAND_UNKNOWN = 0;
PRINT_HIGH_QUALITY = 1;
PRINT_DRAFT_QUALITY = 2;
PRINT_&_INTERNAL_DISTRIBUTE = 3;
PRINT_&_COMPLIANCE_DISTRIBUTE = 4;
}
CommandType command = 1; //may not be NULL, i.e. the value-field is required
repeated google.protobuf.Any dataSet = 2;
// The ‘Any’ message type lets to use messages as embedded types without having
// their explicit definition in .proto. An ‘Any’ contains an arbitrary
// serialised message as bytes, along with a URL that acts as a globally unique
// identifier for and resolves to that message's type
}In the second case, i.e. when we need to pass large data-sets and/or, for example, each CommandType may have different data-set, we need to modify the signature of the RPC call. The gRPC passes large files/data-sets via streaming. Each streamed message may have the command and the data-set. The command passed with each message is optional and may be used to avoid complexity in later identification of which command relates to which data-set on the receiving side. So, the RPC call should look in this case like this:
rpc executePublish(stream CommandRequest) returns (stream RetortResponse) {}plus, the keyword “repeated” in the message Command can still be used if the amount of data for this command is small enough.
A figure below illustrates a potential taxonomy of Microservice invocation for function and data.
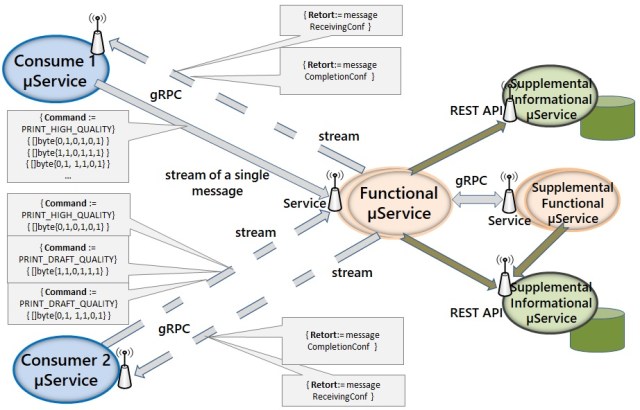
Microservices that can effectively interact and perform relatively complex business logic benefit from gRPC the most. This is not about resurrecting a monolith because compositions of Microservice can be configured and re-configured dynamically, as needed to support new business integrations. In the collective work, business terminology uses “integrate” for capabilities and functions while actual business services, including Microservices, interact, i.e. never integrated because this deteriorates their purpose.


