People like rubbish because it is convenient…
- Almost a Fairy-Tale about Microservices
- Are We Clear about What is What?
- Let’s Expose the ‘Devil’ that is Sitting in Details
- Distortions 1 to 12
- A First Glance on Modelling Distortionless Microservices
Almost a Fairy-Tale about Microservices
Once upon a time, technology was conquered by marketing buzz and started to use senseless names for its entities and methods. For example, a first standardised platform-agnostic interface for interactions between applications and systems was called “WebService” while it was not a service (only an interface) and was not exclusively about the web (it was immediately mapped on other protocols). Then, a service-oriented Principle of Statelessness – it was named this way for the populistic purposes to indicate possible support for massive transaction loads while the formula of this Principle never required statelessness. Nowadays, we have the term “serverless”, which in plain English means ‘without server’ despite it stands for ‘a server I do not control’. It’s a classic uneducated mixture of things themselves and how they should be used. No person who is not technology savvy can comprehend this and, therefore, can be misled. But this is only a beginning.
We have a technology notion called Microservice, or “Microservice Architecture”. Let me put off discussing a simple question – is it a real architecture or just a sound word? The person[1] who articulated this as an architecture – Mr Martin Fowler – wrote, “Microservice Architecture” … to describe a particular way of designing software applications as suites of independently deployable services. … there is no precise definition of this architectural style”. Great! Now I understand why I’ve found so many opinions about Microservices – no definition means chaos. Are we smart enough placing the industry and our own companies on such ‘thin ice’?
Are We Clear about What is What?
Since we do not have a definition of Microservice from the original source, I permitted myself to compose up one, which, in my opinion, reflects the intentions of Mr. Fowler. Thus,
a Microservice is an autonomous and independently deployable component or an application organised around a simple Business Capability or realising a business function.
In essence, a Microservice plays the role of a leave SOA Service, i.e. it is focused on a single non-decomposable Business Capability of single business function (action/operation). However, it is not compliant with the majority of principles of service orientation – this is why it is a component or an application rather than a service. For comparison, I’ve quoted the definition of SOA Service provided in the OASIS RM for SOA standard as shown in the figure below.

The design and development of a software entity are usually driven by certain principles that together with the definition allow people to distinct this entity from others. Mr. Fowler has not defined any principles for Microservices, but enumerated several characteristics, as he called them, which, in effect, may be not necessary principles. In the table below, I have listed Principles of Service-Orientation and a few explanations to provide my readers with information that can help them to form their own opinions on whether Microservices are small SOA Services or just pretend to be such.
| Microservice Architecture | SOA Service |
| 1. Products not Projects (Martin Fowler) | SOA Service is independent, self-consistent entity that may have its individual ownership |
| 2. Smart endpoints and dumb pipes (Martin Fowler) | Standardised Service Description defines ‘smart’ implementation behind dumb interfaces/end-points |
| 3. Decentralized Governance (Martin Fowler) | SOA Services segregate their design, organisation and execution from their use/governance |
| 4. Decentralized Data Management (Martin Fowler) | SOA Service encapsulates its business capability and meta-data enforced on any supplied data |
| 5. Development Infrastructure Automation (Martin Fowler) | SOA Service is tolerant to the methods of its implementation |
| 6. Design for failure (Martin Fowler) | Properly realised SOA Service is robust and shields their internal problems from consumers |
| 7. Independent replacement and upgradeability (Martin Fowler) | SOA Service is an independent entity with an independent replacement and upgradeability |
| 8. Single Responsibility Principle (Robert C Martin) | SOA Service realises a business capability regardless its complexity |
| 9. Loose Coupling Principle (Saravanan Subramanian) | SOA Service Loose Coupling |
| 10. Domain Driven Design (Saravanan Subramanian) | SOA Service is business capability focused |
| 11. Separation of Concerns (Saravanan Subramanian) | SOA Service Separation of Concerns |
| 12. Principle of Hexagonal Architecture (Alistair Cockburn) | SOA Service is driven by its owner or provider |
| 13. | Standardized Definition of Service Contracts |
| 14. | Service Abstraction (in Service Description) |
| 15. | SOA Service Composability |
| 16. | SOA Service Relative Autonomy |
| 17. | SOA Service Discoverability |
| 18. | SOA Service Execution Context |
| 19. | SOA Service Reusability |
As you can see, Microservices have just a few principles but several implementation guidelines. Together, they barely qualify the Microservice realm for ‘Architecture’. In the real world, Architecture tries to avoid dictating how to build and, instead, points on what to build and why. That is, Microservices are much more alike a guided technology.
I have failed to find much integrity among Microservice characteristics. Though, many of them target an easiness of Microservice development in disconnect with consequences and with to-be delivered values. A constant business requirement of delivering IT products faster never assumed the latter may be made in a haphazard manner where robustness, consistency and accuracy may be sacrificed for the time-to-market. In my 25+ year practice in IT, I used to believe in if a person proposes A, s/he has to address B and other relatives and consequences, but I haven’t noticed such precision in Microservice technology.
Let’s Expose the ‘Devil’ that is Sitting in Details
Distortion 1.
Microservices may be isolated from an execution context. Description of Microservices refers to ‘context’ only with regard to DDD and monolith applications. At the same time, the term ‘execution context’ was standardised a few years before it Microservice Architecture was described. The definition of execution context is provided in the diagram above, but no one element of it is required or considered in the Microservice design and implementation.
In contrast, all business functionality is contextual. For example, if a Microservice M1 calculates a price of a Mutual Fund before end-of-day, Microservice should be aware where it is used – in the UK or in the US because the formulas in these countries are different. If we follow a Single Responsibility Principle, such Microservice is useless because we need another Microservice M0 that should organise 1) a Microservice M2 that would provide information about the local context – the country of usage, 2) a Microservice M3 that defines the local time according to the Fund/Stock Exchange in the Fund location, and 3) specify the Microservice M1country and time to choose correct formula. If we delegate these organisational activities to M1, we violate the Principle of Separation of Concerns and Single Responsibility Principle; also, some advocates of Microservices can blame us in creating a new monolith.
The inability of modern Microservices relates to the business execution context explains why Microservices are used predominantly inside Applications, i.e. in the same execution context. Also, it is noticeable that when people talk about external APIs, a notion of Microservice is usually omitted. Such APIs cross contexts and push contextless Microservices into the secondary roles.
Distortion 2.
A Microservice composition is a Microservice. Microservice Architecture does not articulate whether we may accept a composition of several Microservices as a Microservice or it is a monolith. Mr Fowler has written, “If you find yourself repeatedly changing two services together, that’s a sign that they should be merged”. Well, an alternative option is to review their interaction mechanism because merging will violate Single Responsibility Principle.
Here is an example. Assume we have a function “place the document in the folder”. It seems like a simple single function that can be realised as a single Microservice. If you ask about this among business stakeholders, the answers will vary depending on who you ask. If we look at it from a capability perspective, it will be a complex composite capability: we need to find the document, we need to find the folder, we need to open the folder if it is closed, we need to place the document in the folder. An SOA Service will not have any problems with it – it will follow the business logic and ready to externalise small functions like find/open to other SOA Services if and as needed with no impact on its consumers, all behind the interface.
Distortion 3.
Decentralized Microservice Governance is required. This topic overlaps with several others and I kindly ask for your excuse for possible duplications of the following:
Repeatable Statements. We have a problem with this topic because characteristics that have been supposed to portray a Microservice had been mixed with the usage of Microservice (apples and oranges). This is a common IT mistake. Particularly, we should not forget that Microservices are created and used/executed not in a vacuum but within an enterprise/company.
A company hires developers of Microservices and, therefore, has exclusive rights to decide how to govern its Microservices. There may be Application-scope registries, department- or LOB-scoped registries for Microservices. What should be avoided is a Team-scoped registry because this reduces knowledge sharing in the company and reusability of Microservices as well as facilitates duplications (not resilience) of solutions.
Distortion 4.
Microservices to be designed for failure. Even in the section dedicated to this topic, Mr Fowler pointed to “ that applications need to be designed so that they can tolerate the failure of services”. The rest of the text talks about monitoring. That is, no guidelines what does such design means are provided and it seems that it relates to the Application, not to the Microservice.
At a glance, it is a great principle… unless some people read it as permission for a Microservice to fail at run-time. If so, it is possible to conduct minimum testing for the sake of time to market.
I understand this principle as a development of the run-time fail-over with no relying on network distributions and clusters that do not help if the bugs are in the code. I’ve seen Microservice Patterns that help Microservice to “die fast” (Fallback and Circuit Break), but have not seen patterns for Microservice survival and robustness (except Sib and Tandem patterns that I developed). For example, we are building either a Microservice with an event-based interaction mechanism or a RESTful API – where in the design a self-healing (design for failure) is hidden[2]?
Distortion 5.
Microservice has to own functional data. I will talk later about Data Management with regard to Microservices and I have rephrased the popular statement that Microservice owns its data. What does mean “its”? Since Microservice is about business function/capability, the data is supposed to be business data. In this case, let me refer to the Repeatable Statements above.
If someone does not know, I am happy to remind that all Microservices and business data are owned by the company. An Application, component or Microservice may own only the data it cannot operate without. Such data represent the state, or a cache, or indicators/markers/flags in the data tables, and alike. This is called technical supplemental data.
If a Microservice owns business data in any type of storage, this constitutes a fatal risk for the company – if this Microservice fails, the company loses access to its business data, which is unacceptable. In contrast, SOA Service does not own any data and free to be moved or included in any new composition or application via external re-configuration. This is much faster and much easier than managing multiple and, possibly, contradicting ownership schemes.
Distortion 6.
Decentralized Data Management is required. This is the most controversial topic in the Microservice realm because it tries to connect two relevant but profoundly segregated matters – activities/operations and data. Functionality/actions/activities are the essence of what business does along its entire history. Data is a very important reflector of our reality, but the same data can be interpreted is as many ways as we have interpreters.
Since we talk about Microservices set around “Organized around Business Capabilities”, which comprise business functions and resources needed for its realisations such as specialists/skills, data, technology, laws etc., the business functions/operations, not data, drive analysis, organisation and management of data, not the other way around. However, Technology is predominantly about data and developers subconsciously focus on data – this explains why IT propagates data centricity to business. If a business changes data interpretation, the best deep machine learning of data will change its predictions; c’est la vie. Unfortunately, this explanation does not help much in setting proper inter-positioning between functionality and data for Microservices.
Microservices have appeared as a means of decomposing monolith applications for the purpose of making then more flexible and manageable for the cost of increased architectural and managerial complexity. At that time, companies had multiple different data stores already, which were shared between applications, services and systems. In spite of the big number of stores, the industry had clearly identified a need in corporate business data models mandatory and shared if not in the entire company than in its division or LOB. An absence of such models resulted in multiple severe business mistakes and losses. Apparently, the business data models required management in the scope of the model, especially in the highly dynamic market.
Historically, the relational design of data storage anticipates data sharing. All know that management of the data updates in the concurrent processing is not a simple task and requires efforts of more than one person and team. The same relates to non-relational data storage – documents stored in them are created for the purpose totally different from the convenience of Microservice developers and contain a variety of different business information. Since a Microservice is dedicated to the minimally viable business function, working with a document usually demands multiple Microservices, which have to share it with no guarantee of overlapping avoidance.
A Decentralized Data Management in Mr Fowler interpretation is about each Microservice, i.e. each business function, to own related data. Well, to be more accurate – each Microservice should own its data. “Own” has been transformed into “manage”, though the meaning of “its data” remains undefined. Because of this ambiguity, developers reinterpreted “its data” into the business data the Microservice processes. It is not a surprise that nobody was stopped by the obvious conflict of ownership – IT used to believe that it owns the data it processes. The GDPR regulation has proved that this is a wrong belief and that all data in the company is, first of all, a company’s responsibility. In the previous section, I have explained that ownership over data a Microservice may possess. So, we have a dilemma: either the concept of a Microservice-Owns-processing-business-data/storage and nobody else can access and modify this data regardless the “health” condition of this Microservice or this concept is wrong and has to be eliminated to allow Microservices to share data in data sources. How to share the data is a totally different question.
Let’s take another viewpoint. A company contracts a supplier and receives bulks or streams of data packed for the long run. This includes considerations about constraints of the delivery channel – the bandwidth, time of encryption, resilience, etc. You can trust me on my work here – nobody would ever count in the consumer’s Microservices and their individual lifecycles. If Microservice-Owns- processing-business- data/storage, the data consumer organisation should split data flow into segments for different processing micro-functions for sake of Microservices. If anyone thinks that this is feasible from the company perspective, I recommend taking the second thought.
Data Management decentralisation existed before Microservices appeared[3]. They were split by business domains and risk levels. Now we are proposed to split data at the level of discardable Microservices with relatively short lifecycles. What business or management value such a proposal offer? Is this an easiness and speed of development and testing – no concurrency in data access means no need for related testing. Is this a business value? I’ve read a statement like this, “In a successful Microservice architecture, there is no cheating – you can’t go behind the published interface and read or write in the Microservice’s persistent storage.” Thus, in order to update data, the application has to wait for the single instance of the Microservice to become free to perform this update operation. Yes, one instance because if there is more than one instance having the same data store, we get a data concurrency again; if we have a store per Microservice instance we create potentially terrible data inconsistency (eventual consistency is not acceptable in many cases despite developers’ belief). I can conclude that Microservice-Owns- processing-business- data/storage is nothing more than an unjustifiable convenience for Microservice developers.
Martin Fowler mentions that “microservices also decentralize data storage decisions”. He continues, “Microservices prefer letting each service manage its own database, either different instances of the same database technology, or entirely different database systems – an approach called Polyglot Persistence.” I am fine with the recommendation for a Microservice manages its own data base for its state data – from creation till elimination per Microservice engagement session. If this database is supposed to keep business data longer than for this session or if the database is for maintenance by dedicated support, the cost, risks and complexity of such solution are prohibiting for realisation. If you still disagree with me on this, please, try to answer following question:
- Mid- to big-size companies have many different data storage for different purposes. Does Martin Fowler say that a small team of developers should have an authority to make decisions about decentralisation of data storages that they have no idea about?
- Even Martin Fowler notes that the same business entity, like Customer, is represented via a different set of attributes depending on the business domain it is used in. So, several domain-focused Microservices should split the mastered (golden version of) Customer entity and will be able independently modify its attributes in own databases. Many years ago, the industry found that trying to manage integrity between separate parts of the entity under different ownership is terribly dangerous for the company. It is cul de sac. Are Microservice developers recommended stepping on the same rake again?
- “Microservices prefer letting each service manage its own database, either different instances of the same database technology”. Well, if the database contains business data, what would happen with this it and with the data when the Microservice fails, or gets removed from the Application, or should be replaced by another Microservice?
If Mr Fowler has meant that Microservices own and manage business data in their own data storage longer than the duration of Microservice invocation, it is simply a dangerous and objectionable model. If Microservice developers decide on business data ownership and logical organisation of business information, may I ask – on what grounds? What Microservice developers know about the corporate information models, corporate needs, market trends, and regulations? If such ownership model for Microservices assumes that companies should disassemble all their legacy systems for the sake of Microservices and do this immediately when a new Microservice would need some data to form the data storage? I do not know about you, but I know that this endeavour is known as “boiling an ocean”. Can any company afford this and what for?
I see a clear disconnection between this characteristic of Microservices and reality. I do not believe it is accidental; it is rather negligence rooted in the populistic intention to 1) recruit developers onto technology by easing the work regardless the consequences, 2) attract IT mentality that wants to see the very data, not business or customer, as the centre of the company, and 3) to allow a limited development of a single developer/team to ascend irrespective the business rational and needs.
Distortion 7.
Microservices to avoid Two Phase Commit. A Single Responsibility Principle for Microservices looks good at a glance, but has the dark side as well – it cannot be realised in practice. Every Microservice has at least two business responsibilities anyway. One is the business function (capability) and another one is providing data for an Audit. Every action performed by Microservice regarding the function must be logged for audit purposes. Auditing is one of the cornerstone business management functionality.
Here is a simple example: a Microservice performs its work and has to persist the result, but it also needs to report this event by firing a notification (or sending a message). Both actions must succeed or none of them. Moreover, both of these actions should be logged for auditing. Altogether, we have not one function/action for a simple Microservice but three and this is a regular case (a Principle of Single Responsibility is a nice abstraction after all). We have a classic case for Two Phase Commit (2PC) transaction as we used to have in monolith applications. Such 2PC takes place within the Microservice’s body and it is absolutely unclear why this has to be avoided.
However, using 2PC across Microservices imposes significant problem due to the Microservice independence, i.e. such transaction in one Microservice may not lock other Microservices. We have to either relax the notion of independence or replace 2PC by a distributed transaction across Microservices. The latter is a subject for a special discussion related to the “Distributed Transaction for Microservices” pattern A meticulous analysis of such transaction leads to understanding that so called Compensating Transaction is not possible or useless in many cases, especially if the frequency and volume of distributed transactions grow. This is exactly the instance where the business agrees to accept a risk of inconsistency or eventual consistency.
Distortion 8.
Microservices are products with maximum granularity. A Microservice characteristic states that each Microservice is a product. This immediately leads to the statement that each Microservice must be treated as a product, i.e., at least, supported as a product. If a company had a couple of dozens of systems and applications – the products – before, an appearance of Microservices can increase this number in a magnitude of 100x. Had anyone of promoters of Microservices ever thought about this? Experienced people know that SOA Service, as well as Microservices, are not programming objects and require quite different treatment because they can, in contrast to objects, put the company down. In other words, proper product support is essential. The finer the granularity of Microservices, the bigger their number.
In practice, Microservices appear with fine-grained APIs like object’s methods, especially with RESTful APIs with its GET, PUT, POST, etc. methods. When the number of such Microservices reaches hundreds and even more, the management and maintenance of them can become a show-stopper. There are two more arguments against fine-grained interfaces of Microservices:
- Microservice is about business function, which, usually, is not immutable. A minor change in the functionality can cause related changes in the implementation and, if the Microservice’s interface is fine-grained, it is more likely it should be changed as well. The interface change impacts all its consumers, which can cause a chain-reaction effect across development teams
- Microservices are enforced to work with corporate semantics and data, which can be changed (even via Microservices). However, Microservices usually exchange data. Therefore, a change in the data semantics will impact fine-grained API a great deal.
An alternative to fine-grained RESTful APIs exists already – it is consumer-driven requests for GraphQL APIs. In this case, it is the consumer decides what data to be returned and the data set may quite coarse-grained.
As an aside comment here, I’d like to mention that Microservices are not about data by nature and seeing them via a prism of REST is error-prone. Microservices are about business functionality and a relatively new API like gRPC allows ignoring data and operating with Microservices in full at the functional level. This model is much closer to the logic of business operations than the data-centric approach.
Distortion 9.
Microservice isolation is good for Microservice Collaboration. Industry experience for many years with engaging of multiple independent or barely-dependent components and service into collective work teaches us pros and cons of such patterns as Collaboration and Cooperation. The popularity of marketing statements about collaboration has obfuscated the meaning of this term and its basic principle for technology. Many people and even standards addressed the topic of collaboration vs. cooperation because of its deceptive easiness and political correctness. In practice, the collaboration pattern implementation failed all the time regardless applied efforts.
Just to remind my reader: collaboration means that every participant of the collective work makes the goal/purpose of this work its own business goal. In contrast, cooperation pattern does not require any individual dedication of the participants, they are used as-is by the third orchestrating party. In reality, when collaboration (as collective work) is formed, each participant – Microservice – has to modify its implementation to become aware of both its neighbours, i.e. about other Microservices and their events that our Microservice has to listen and react in certain way according to the collaboration requirements and about other Microservices that listen to his special event–notifications addressed to them. If our Microservice participates in two or more choreographies at the same time, it has to adjust itself for each applied choreography, i.e. has to be in re-development all the time. This is not only the con – a failure of any participant (recall, a Microservice failure is expected) crashes the entire choreography; it is extremely fragile [see the example of its application in the case of hurricane Katrina in the USA].
So, why Mr Folwer explicitly outlined “microservice preference towards choreography and event collaboration leads to emergent behavior”? The answer is easy – developers think that they can develop individual Microservice in isolation, with its event firing and listeners. The fact that the next Microservice must be developed in full dependency on the first one is the job of another developer/team. The “event collaboration” is defined as “Instead of components making requests when they need something, components raise events when things change. Other components then listen to events and react appropriately”. First, collaboration is not about “of components making requests when they need something” it is the collaboration needs something the component should perform. Second, why a Microservice M1 should listen to the events of Microservice M2 if they are isolated? If a business task requiring collaboration comes up when the Microservices M1 and M2 run already, the M1 should be re-designed, rebuilt and re-deployed to listen to M2 and execute special related activity. An illusion of independent work and unawareness that each Microservice-participant in choreography becomes a point of failure contributes to the aforementioned preference.
The cooperation of Microservices is free from both cons of collaboration. Cooperation assumes the existence of a special Microservice that coordinates the invocation of the Microservice-participants, resolves all failures of them and can be created and applied after they are deployed. If a Microservice-participant can handle concurrent API requests or events, it can be engaged in multiple cooperative works simultaneously even without knowing this. The only point of failure in this pattern is the orchestrator itself. However, it is much easier to eliminate this point with several patterns than to protect each participant. The teams may continue developing their Microservices as usually while an additional developer has to focus on the orchestrator and its robustness.
Distortion 10.
Autonomous Microservice Principle. This principle states, “An Autonomous Microservice can only promise its own behaviour by publishing its protocol/API. All information needed to resolve a conflict or to repair under failure scenarios is available within a service itself, removing the need for communication and coordination. … Isolation is a pre-requisite for autonomy”. I’ve demonstrated already that isolation is a myth about Microservices. There are only two differences between an Autonomous and Isolated Microservices
- Autonomous declares that it “can only promise its own behaviour”
- Autonomous declares that the “repair under failure scenarios are available within a service itself”.
To illustrate the fallacy of the first statement we can return to our previous example – “place a document into the folder”. We have established already that this described function can be decomposed into 5 finer-grained functions. This means we can create a single Microservice to orchestrate the execution of the 5 functions to obtain the desired result. The “own behaviour” of this Microservice is an ‘orchestration’, it is not a monolith. Thus, the orchestrating Microservice promises the actual result/outcome of the work – a document in the folder. This is how business works and limiting Microservice outcomes to their behaviour only is impractical and irrational.
The part of the Principle “…All information needed to resolve a conflict or to repair under failure scenarios are available within a service itself, removing the need for communication and coordination” is much more controversial. If a conflict is inside the Microservice, i.e. a bug, the resolution – a bug fixing – is outside of the Microservice, isn’t it? If a conflict is outside the Microservice – in interaction with another Microservice or with the run-time environment – the Microservice itself cannot resolve it in isolation: the counterpart has to be involved or it is a bug (again). If this is a failure of communication caused by the network, only the network can fix it though the Microservice can try to work around – re-try connection or engage a partner in the Sib pattern, but this happens not inside the Microservice.
Due to its nature, a Microservice cannot resurrect or bootstrap itself – it is a client-server model. Microservice can repair only a failure, which is under its own control in full, e.g. re-establish lost connectivity with the database. If the initial connection was provided to the Microservice from outside, even this cannot be resolved inside. In contrast, the SOA Service interprets relative autonomy with regard to the run-time environment, i.e. autonomy is a minimisation of the service dependency on the environment, which would make sense for Microservices as well.
Distortion 11.
Microservice Flexibility. Since the major purpose of a Microservice is realising the certain business function, it makes sense to apply “business flexibility” term. Business flexibility is set around ability of the solution/entity to adapt a business change promptly and dynamically, as well as to adapt promptly and dynamically the consecutive change of the changes. There is a method that provides a quantifying estimation of business flexibility. This method operates with the cost of adopting a change, the cost of changing that change and the time to market. For example, if adoption of a change is quick and cheap due to direct code change in the product, the cost of change of such implementation of the change may be high and increase continuously, i.e. an overall solution of direct code modification has low flexibility.
Usually, business flexibility is gained not by re-developing the code all the time, but by re-composing already existing entities. With regard to Microservices, this means that the later have to have a very rich and flexible means of interaction with others that can be useful in new compositions. A Microservice that has a narrowed REST interface and provides a predefined query into the data storage is an immature baby-level inflexible solution like a database driver on HTTP steroids.
The Microservice flexibility comes with the cost of designing and developing extra hooks and connections/end-points immediate requirement does not state, but the business function to be implemented considers very well. A reference on the high speed of development and on that the team can produce a new Microservice/version with adjusted functionally in a matter of hours, does play here – either it increases the number of Microservices, i.e. complexity and cost of support (to be additionally funded), or if it goes with versions, the version management and support for existing consumer base will slow everything down a great deal.
Distortion 12.
Principle of decentralized control of languages. Mr Fowler has said, “There is a bare minimum of centralized management of these services, which may be written in different programming languages” “to take advantage of the fact that different languages are suitable for tackling different problems and use different data storage technologies.” This is a dream of IT for many years. These days, when many new languages have appeared in the industry, this idea becomes more appealing… for developers.
If you ask business analysts, architects, project/product/programme managers and support specialists, they would likely say that 1) multi-language development introduces additional complexity and new problems to deal with. Here are a few examples of such problems: code quality control, code security, message/event content, fault tolerance, support availability like bug tracing and patch management, etc. And all these individual problems have to be tackled at scale.
There are no objections that major development layers like presentation, business and back-end would be addressed with different programming languages. This practice is well-known in application development, but it does not mean that each developer is in right to choose a certain language for the Microservice because s/he is interested in adding it to the resume. Recall, a Microservice is a product and has to be maintained appropriately. A choice of programming language for Microservice implementation only partially depends on developers’ decisions. Another part of this decision is on corporate policies and rules.
A First Glance on Modelling Distortionless Microservices
In the end, let me try to model the appearance of Microservices if we resolve all discussed distortions.
- A Microservice is a programming product that is designed and implemented according to several principles of service orientation, focused on the realisation of a small, non-decomposable business function and may be independently built and deployed.
- Microservice may have a few interfaces represented by different communication protocols, e.g. APIs and event-base ones.
- Microservice has a working body that implements predefined functionality and delivers a certain outcome.
- Microservice preserves loose-coupling between its interfaces and working body. Microservice is free to change its body in any way until the change impacts business functionality and outcomes. Changes of the interface(s) are possible but highly undesirable. The more granular the interface is the more negative impact this causes to the Microservice consumers.
- Microservices are built for reuse.
- Microservice can participate in as many compositions with other Microservices (also known as application) as needed and can organise as many such compositions as needed.
- Microservice has to consider its execution context, especially in defining its SLAs (per interface). Business regimes change per locale.
- Microservices can work within Applications or SOA Services. Microservices can cross Application boundaries, but may not cross SOA Service boundaries (which is possible via SOA Service interfaces only). Cone in the Microservice boundaries may not cross Microservice boundaries.
- Microservices may be managed/governed centrally or de-centrally depending on the execution context and business needs.
- Microservices should be designed and deployed in a fault-tolerance manner or offer other means to fail-over for any types of failures – internal or external. This does not mean that Microservices must contain fail-over means inside their bodies; these means may belong to Applications or SOA Services and be available to other Microservices, especially consumers.
- Microservice should be able to process any data presented in the meta-model owned by the Microservice. This is a precondition for composability, reuse, scalability and flexibility. Microservice may own only its technology supplemental data, i.e. the data is cannot perform its business functionality. Microservice is tolerant to the data management means.
- Microservice’s body can encapsulate any internal transactional operations. Microservice may be used in any distributed transactions that do not require Microservice locking. Microservice is not obliged to maintain transaction-related data for the duration of an external transaction. A cross-Microservice distributed transaction is usually managed by a special dedicated Microservice-orchestrator. Organising collective work of Microservice via choreography patter is not recommended because of fragility and very low scalability for participating Microservices.
- The granularity of Microservice should not necessarily be reflected in the Microservice’s interface(s). The more coarse-grained interface is, the more Microservice is useful and convenient for its consumers, i.e. the more it reusable and flexible. It is not recommended exposing internal data models of the Microservice via its interface(s). If the only operations needed are CRUD, it is not business functionality and, thus, no Microservice can be used for this.
- Microservice can be designed, built and tested by different people. Microservice can be designed and built in relative separation from other Microservice while all aspects of intercommunication of Microservices have to be agreed and appropriately designed in the context of other Microservices to the best knowledge of the development teams. There have to be special design-specialists responsible for Microservice-based applications and integral interaction of each Microservice with others for the sake of solutioning given business task.
- Microservices should be minimally dependent on the run-time environment.
- Microservices have to be accurately documented (automatically or manually), especially their functionality, contexts where particular SAL may be delivered via a certain interface, and all offered interfaces (end-points/APIs/protocols).
- Microservices in the company/LOB/Division should follow related policies with regard to used programming languages, error-handling, quality assurance, security, compliance, manageability and support operational patterns.
In the modern economic environment, there are two major drivers for competitive advantage:
- the adaptability of market changes caused by regulations, technology innovations and cultural evolution
- time to market of produced products and services.
It is not secret that market changes are usually much more complex that modification in one or a few business functions. So, the companies are in need of integral solutions comprising more or less complex tasks where Microservices can be the means but not the final results. In the diagram below, I tried to put together characteristics of current Microservice Architecture and modelled Distortionless Microservices for comparable complexity. The values shown in the diagram are estimated against both criterions: change adaptability and time to market.
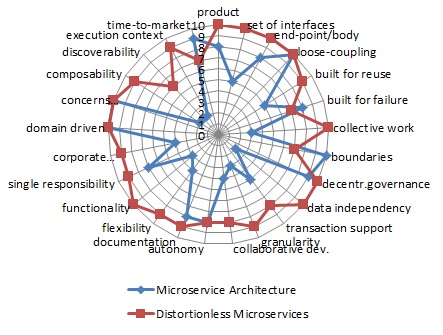
As has been expected, the Distortionless Microservices appear more suitable for realisation in modern companies.
[1] Wikipedia: “Dr. Peter Rodgers introduced the term “Micro-Web-Services” during a presentation at the Web Services Edge conference in 2005. On slide #4 of the conference presentation, he states that “Software components are Micro-Web-Services”. Juval Löwy had similar precursor ideas about classes being granular services, as the next evolution of Microsoft architecture. That time, everyone wanted to join the stream of ‘services’ like in our days everyone what to be ‘architect’. “Services are composed using Unix-like pipelines (the Web meets Unix = true loose-coupling)”, which contradicts OASIS SOA standards.
[2] Let’s take a look at one of the best platforms for API/Microservice design and development – the MuleSoft’s AnyPoint Platform. It takes care about a lot of Microservice characteristics, but keeps silence about self-healing, exception handling and fail-over.
[3] Big business units like LOB or Divisions that cover certain business domains, can create and maintain their master-models of related data and together with others form a corporate unified data model.


